LegalTech – from Theory to Practical Applications
In a previous blog post, we explained what LegalTech is; a collection of technology solutions that help lawyers and laypeople interacting with the law to process, interpret, and use legal data. However, to understand the importance of the subject and its potential, it may be worthwhile to look at some practical examples of software already in use today.

Source: DALL E 3.
When looking for examples, it is worth considering the significant differences in the uptake of LegalTech tools between, for instance, the US and Europe. The US is a leader in digitalization, which has a significant role to play in terms of such tools. This is not only due to the high level of venture capital and the American entrepreneurial mentality but also to the specificities of the common law system. In common law countries, court judgments are the primary source of law, which initiated the process of digitization of judgments as early as the 1960s (mainly to support efficient searchability). In the Anglo-Saxon litigation system, discovery is a prominent feature, with the rapid emergence of e-discovery tools in electronic format, which is also one of the most common applications of legal technologies.
In common law litigation, knowledge and reasoning are also of paramount importance, and tools to analyze judges, opponents, or cases based on Big Data have quickly emerged. In these countries, public access to documents and legal data has been made possible by frequent public access policies, which differ from those in continental jurisdictions. In the US, for example, documents from federal high courts are generally public, which offers great opportunities for legal data analytics companies. And of course, many companies have taken advantage of this opportunity.
Examples include LexisNexis, a provider of legal research, business information, and analytics services, Clio, a cloud-based legal case management system that helps law firms with administration, billing, and client management tasks, and Relativity, an e-discovery platform that helps lawyers process and analyze large amounts of data, especially in litigation.
Somewhat in contrast, in the case of the European Union, we see that the attitude of the countries here, which operate under continental law, is generally more cautious about technological developments. This can be seen, for example, in the forthcoming AI Act, which classifies AI-based services (and, for example, the Large Language Models – LLMs that run in the background) into risk classes and sets the regulations that apply to them accordingly.
As already mentioned, legal technologies are often based on existing processes, using “traditional” machine learning, for instance. The development of concrete applications essentially involves the domain adaptation of these, i.e. the integration of software development knowledge, Artificial Intelligence expertise, and legal knowledge. To make this kind of synergy easier to understand, let’s take a concrete example and follow the necessary development steps in a nice sequence.
This example will illustrate what solutions are needed to build a search engine based on legal documents, making it more cost-effective and faster for a law firm, for instance.
Of course, the first step in such a case is to gather the necessary documents, which is not trivial. For each type of document, the rules differ from country to country as to whether they are public. A further issue is that some documents (for example court decisions in Hungary) can only be disclosed in anonymized form, while in other countries there is no such restriction.
In fact, the anonymization must be solved by the publishing organization or office, but we must note that even this step presupposes the presence of Machine Learning (ML) tools. Of course, the process can be solved manually, however, like many other processes, it is much more efficient if we turn to automation. The proper names, names of organizations, and possibly geographical places present in the texts are referred to as Named Entities in summary. Of course, in the case of legal texts, these may be supplemented by other types, e.g. the names of the courts of jurisdiction. These must first be identified in the text, a task that can be carried out by the Natural Language Processing task of Named Entity Recognition (NER). Given labeled training data, the goal here is to develop a ML model that recognizes the relevant elements of the text and either discards them (e.g., with the string “####”) or replaces them (e.g., if the text contains Sam Altman, it replaces it with John Doe).
There are, of course, other issues here. There may be cases where the anonymization of a person’s name does not in itself make it impossible to identify the person. Suppose that the name of the victim is removed from a particular piece of litigation. However, the information in the text reveals that the victim is a 97-year-old woman living in a small town of 1000 inhabitants. If the approximate location is also revealed in the litigation material, this information will almost certainly allow the person to be identified without mentioning the name of the person. In such cases, we say that the document is in fact only in pseudo-anonymized form. The question is whether this can be considered a sufficient solution in practice.
The next task could be to make documents searchable. If we move away from traditional (simple character-based) search, we are faced with the problem of semantic search.
The basic idea here is that it should not only be possible to search a huge number of documents by keywords, but that the semantics and meaning of the documents should also become searchable. What does this mean in practice? A typical legal search method is to start from a given set of facts and look for relevant textual references. The aim is to find regularities and precedents relating to the facts we are interested in, which can be used to infer the legal consequences of the case at hand.
In this case, the subject of the search is an abstract statement of facts, in which case the search for exact character matches would not even make sense. Similar situations are also called semantic searches. Here, the procedure is to transform both the search term (in our case, a statement of facts) and the texts to be searched by means of some AI model. These representations will typically be multidimensional vectors. The search process essentially consists of comparing, for each document, how similar the vector representing it is to the search expression. Simplified to two dimensions, this can be obtained by examining the angle subtended by the two vectors (document and statement of facts). The smaller the angle, the more similar the document is to the search term, and vice versa; the larger the angle, the less relevant the match is to our search.
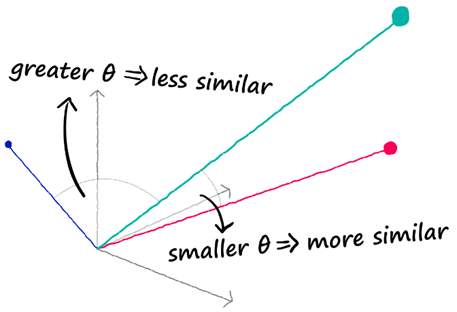
(Source: https://www.pinecone.io/learn/semantic-search/ )
The task to be solved is not to examine the similarity in relation to the whole document, but only to the statement of facts in the document. Again, we can teach a separate classifier model that selects the parts of the document that are related to the search and then performs the search.
Combining the two steps can significantly reduce the amount of noise in search results. The fact-filtering of documents results in more accurate representations, and the semantic search itself significantly reduces the false positive rate. This gives a good chance of obtaining relevant results that are intrinsically related to the case at hand, which in turn significantly reduces the time and effort required for the search.
Although the above is only one concrete application and a schematic search, it is perhaps enough to show how much legal technologies rely heavily on NLP and AI. At the same time, the importance of tailoring generic solutions to the specific domain, for example by adding domain knowledge, which is essential in the field of law, is also very clear.
Exploiting the potential of LegalTech is still a highly researched area and a dynamically growing business. With the rise of Generative AI and the increasing sophistication of industrial adaptation, tasks that can only be performed by experts today may soon become automated routines. Significant progress is expected in areas such as document generation, smart-contracts, and compliance. Together, this will further reinforce the already existing trend towards automation, where jobs requiring human skills are increasingly shifting to the creative side.
István ÜVEGES is a researcher in Computer Linguistics at MONTANA Knowledge Management Ltd. and a researcher at the Centre for Social Sciences, Political and Legal Text Mining and Artificial Intelligence Laboratory (poltextLAB). His main interests include practical applications of Automation, Artificial Intelligence (Machine Learning), Legal Language (legalese) studies and the Plain Language Movement.


