
Smart Search Engines and LegalTech: Why (And How) Do We Create Automatic Summaries of Legal Texts?
The nature of law means that legal problems are often complex and multifaceted, which is often reflected in the length of legal documents. Many documents, because of their function (e.g. court decisions), are expected to deal in detail with all aspects of legal cases. This includes a thorough analysis of legislation, precedents, and specific circumstances. This level of detail ensures that all relevant information is available in one place, which is essential for the legal decision-making process. As a result, legal documents are often voluminous to include all the necessary details for an accurate and complete legal assessment. However, reviewing such documents is often an extremely time-consuming process.
In previous posts, we have already discussed the practical relevance of legal technologies (LegalTech) tools, in more detail. We have also shown, through a concrete example, how solutions known in classical Natural Language Processing (NLP) and Machine Learning (ML) can be integrated into the legal domain. Summarizing the content of individual texts is also an area of long-standing research, which is of considerable interest independently of legal texts. However, as previously discussed, there are specific challenges in applying existing solutions to the field of law.
A summary is a brief but accurate description of a document that summarizes its essence. Such a summary can be produced automatically in two ways. In the so-called extractive summary, verbatim sentences are selected from the original text. In an abstractive summary, on the other hand, new sentences are created that are grammatically and substantively correct and can reflect the essence of the original text. The latter is probably more in line with the way we think of summarization from a human point of view, but both methods have their own advantages.
Why such extracts are useful is easy to argue. Well-prepared extracts can be used, for example, in legal search systems, where you can display not only the relevant documents but also a summary of them. This can help users to judge more quickly the actual relevance of documents without having to read the full text. But, of course, the whole process is most efficient when the summaries themselves don’t have to be written by legal experts. So how exactly can we create them automatically?
Let’s start with the simplest one, the extractive case. In contrast to the abstractive solution, here it is not necessary to use Generative Artificial Intelligence (GAI) since the goal here is to select the most relevant sentences of the text. The result will be much like a good movie trailer, which grabs your attention by selecting the most interesting scenes. The difference, of course, is that while a trailer deliberately hides the punchline, a good summary often contains it, or at least hints at it.
To do this, we need to somehow select the most important sentences in the document, and then somehow prioritize them so that only the most relevant ones appear in the summary. One possible solution is to use some kind of unsupervised ML solution to first determine the number of topics mentioned in the document. This assumes that all relevant topics should be included in a good summary. However, for suitable algorithms, several important decisions need to be made in advance.
After sentence segmentation of the documents (which most natural language analysis tools today can do automatically), we need to say exactly how many topic groups we want to identify in the text. Unsupervised algorithms cannot decide this themselves but expect it as pre-given information.
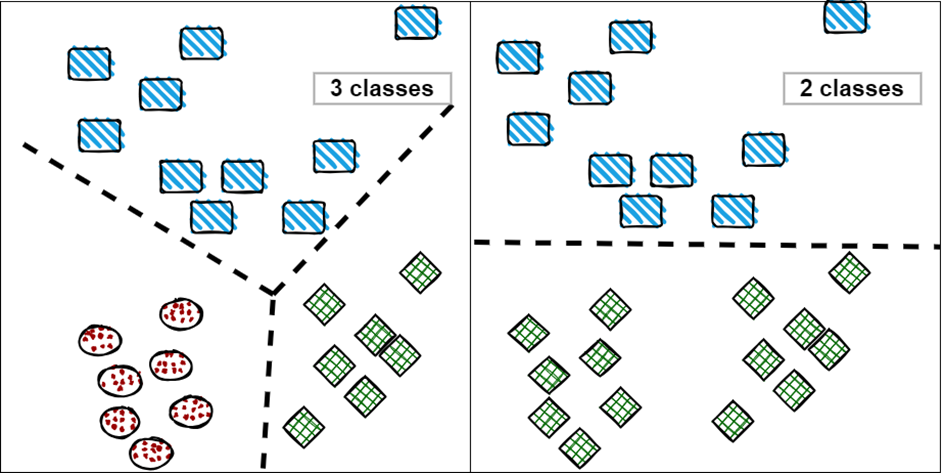
Same data, same algorithm, but different cluster numbers.
Given the number of topics to be found, clustering algorithms, for example, can be used to group sentences by topic. Clustering is an unsupervised machine learning method that aims to organize data into groups, or clusters, based on similar properties. The difficulty is that unsupervised learning does not use predefined labels or classes; the system automatically discovers patterns and structures in the data. This means that if you give the algorithm a different expected group number, you can expect a radically different output. It is important to note that such algorithms do not work on the raw texts themselves, but on the vectors that are trained from them.[1]
Once we have found the optimal number of groups (which is a non-trivial task, to say the least), we still must decide whether we want to put the most important sentences of each group in the abstract, or whether we have more important groups, of which several sentences may be put into the summary. A further decision is how long we want the extract to be overall. Obviously, here we must consider that the purpose of producing a summary is to speed up the work, i.e. the result should not be too long. However, it is also counterproductive if an important element is left out so that you still must go through the whole document to see if it is relevant to you.
The above roughly describes the process of preparing an extractive summary. The advantage is that it does not require pre-labeled training data, i.e. it has a lower cost of entry. On the other hand, as described above, it often requires considerable engineering work to fine-tune the process to ensure that the result is of a truly satisfactory quality.
Abstractive summarization approaches the issue from a completely different angle. It is essentially a process of abbreviating the gist of a longer text, but in this case, by generating entirely new sentences that were not part of the original text. It is therefore different from extractive summarization, which only selects existing parts of the text. The aim of an abstractive summary is to create a short, concise text that retains the main message and key information of the original text while using new formulations and phrases.
Large Language Models (LLMs), such as GPT-3 or GPT-4, are particularly suitable for such a task. These models can understand the context of the text, identify key ideas and information, and then generate new coherent and meaningful sentences based on these. This allows them to effectively create summaries that do not consist of simple copying of parts of the text but reinterpret and summarize the original content. This is much more like how people abstract from the specific text, understand its essence, but keep the important facts when they have to write a summary of it.
The solutions of a few years ago still suffered from teething problems such as generating grammatically incorrect sentences, or grammatically correct sentences that were meaningless. Today, these problems are largely solved, but replaced by new ones.
In addition to the fact that many LLMs operate in a black box fashion, i.e. some aspects of their operation are not transparent to the user, there is also the question of relevance, i.e. what information the model will extract from the summary text. The latter can be controlled indirectly at most by applying techniques familiar in prompt engineering. In addition, there are of course the problems that affect LLMs in general, such as hallucination and the appearance of biases.
The automatic generation of summaries for documents in legal databases is particularly important, as it greatly facilitates the work of legal professionals and researchers. However, the production of automatic summaries is not without its challenges. Due to the complexity and specific language of legal texts accuracy, relevance, and bias must be taken into account when producing summaries. Despite these challenges, the production of automated summaries offers significant advantages in terms of managing legal data and providing rapid access to information. The development of such technologies is progressing steadily, and advances in AI and the field of NLP are further increasing the efficiency and accuracy of these systems.
[1] This is necessary because ML algorithms are based on mathematics/statistics. It is therefore natural that they cannot deal with texts; vectorization is the intermediate process of transforming human language into a form that can be interpreted by machines.
István ÜVEGES is a researcher in Computer Linguistics at MONTANA Knowledge Management Ltd. and a researcher at the Centre for Social Sciences, Political and Legal Text Mining and Artificial Intelligence Laboratory (poltextLAB). His main interests include practical applications of Automation, Artificial Intelligence (Machine Learning), Legal Language (legalese) studies and the Plain Language Movement.


