István ÜVEGES: When AI Poisons Itself; the Problem of Unidentifiable, Artificially Generated Data
The rise of generative artificial intelligence (GAI) has led to a proliferation of non-human created images, text, and videos. New research studies suggest that using purely “synthetic” (AI-generated) data to train new generations of GAI models could have disastrous consequences. Avoiding this makes the obligation to clearly label artificially created content even more urgent if we are to continue to reap the economic and social benefits of AI.
In the world of machine learning, it has been a relatively long-standing practice to use not only original (e.g., human-made) data to train certain models but in some cases also artificially generated data. In the past, this has been useful when there was not enough original data to solve a particular problem. Such a typical case might be when a machine learning system solves a classification task.
The specific task could be, for instance, to develop an application for medical diagnostic purposes that classifies images of moles according to whether or not they contain a lesion indicative of cancer. This will actually be a binary classification task, where we will have to label new incoming images as “yes”/”no” according to whether they require further investigation by a medical professional. While solving this problem, we may encounter a situation of not having enough manually labeled images to train our new machine learning model. Similarly, it may be a problem if we have almost only images of healthy moles. In the first case, the model will not see enough examples to be able to successfully generalize over the task, and therefore its decisions will not be sufficiently reliable. In the second case, since the training data included a strong predominance of images depicting unproblematic skin surfaces, the model is unlikely to recognize problematic future cases. This latter scenario is also commonly referred to as “imbalanced distribution” of the training data.
Data augmentation is a collection of techniques that attempt to remedy a data gap in model training by creating new, artificially generated instances. This generated data can be created by modifying original data entries (augmented data) or by creating completely new data (synthetic data).
In the above example, if we are simply mirroring an image, or perhaps removing some irrelevant details from it, we will end up getting a kind of augmented data. Integrating this kind of augmented data into our original dataset can lead to a significant increase in terms of model robustness and performance. Another possibility is to use, for example, a large language model (LLM) for text generation. In this case, we get fully synthetic data, which we can also use to extend our original data set.
Working with artificially generated data was already known to have an interesting feature. In previous experiments, a number of scenarios have been investigated in which the “value” of augmented/synthetic data was sought. In such cases, an interesting question was what performance could be achieved by the same models using the same amount of original data only, original, and artificially generated data simultaneously, or artificially generated data exclusively. It was a common experience that models trained with only artificial data always underperformed models trained with the same amount of original data. In other words, artificial data, when used along with original, can help the model to perform better, but the original data always leads to better quality results compared to purely artificial datasets.
Generative models, such as OpenAI’s GPT-3, 3.5, or 4 for text generation, DALL-E 2 for image generation, Midjourney, or even Adobe’s Firefly model, have recently burst into the public domain and have required huge amounts of training data. This data is most easily available on the internet and is collected automatically through a process called Web Scraping.
Until recent years, there were in fact no generative models to produce synthetic data of acceptable quality. However, the situation has recently changed, and this synthetic data is flooding the web. This in itself would not be a problem, as there are many examples of the impressive performance of image generators, as well as of how text generation can be a useful tool for both developers and the average person.
The problem is that in many cases the synthetic data are not labeled in any way. As a result, often no one knows for sure whether a piece of content is “original” (man-made) or created by artificial intelligence, except the creator. Based on current trends, it is reasonable to assume that the proliferation of synthetic data on the web will not only continue unabated, but that the rate of proliferation of such content will increase rapidly. In fact, the European Union, for example, is preparing to take serious steps to make it compulsory for content produced by AI to be labeled as such (for instance, to combat disinformation). However, even if this is fully achieved, a comprehensive and worldwide regulation is unlikely soon. Without it, artificially generated content will continue to be generated and fed into the training data of later generation generative AI models unchecked.
Recently, research has begun to emerge on the impact of synthetic data, for example in the training of LLMs. This suggests that the homogeneity caused by the lack of human creativity has a disastrous effect on the performance of generative models, even in the short term.
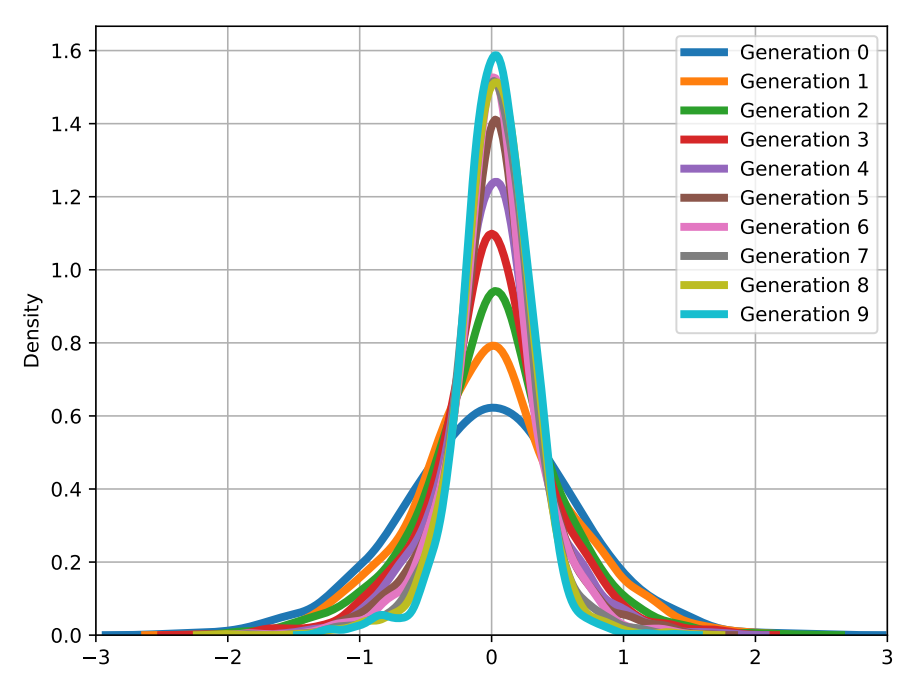
Increasing homogeneity in the outputs of generative models. Models trained on synthetic data start to converge towards a kind of “average” over time, losing the diversity and novelty present in human-sourced data.
In the experiments, researchers investigated what happens when such a model is trained using only synthetic data. The process was repeated several times, each time using data generated by previous generations of models to train the new ones. They concluded that successive iterations of these models produced increasingly poorer quality outputs. This was manifested for instance in the fact that each generation produced increasingly similar, homogeneous outputs for a given task. On the other hand, each generation also lost output quality, for example, images became noisier and more “meaningless” to the human eye.
This phenomenon not only highlights the very limited ability of existing models to produce “creative” content in the absence of fresh human input but also foreshadows one of the potentially most pressing problems of our near future.
For generative AI not to start “poisoning” itself with unlabeled, synthetic data, it needs to be filtered somehow. This is not just a legal issue, but also a technological one, which is inevitable, as explained above. It also raises the dilemma of how the big tech giants that currently dominate GAI development will respond to the problem. Given the ever-increasing data requirements for ever-larger models, it is easy to imagine practices whereby users are manipulated into creating new data over and over again.
The emerging situation has been compared to that of the Geiger counters in the 20th century. The nuclear experiments conducted during the century and the accompanying radioactive fallout released radioactive material into the Earth’s atmosphere. This disrupted the operation of the instruments, as the metal used in the counters itself emitted a small amount of radiation. In response, the search for wrecks, typically pre-war, which contained metals manufactured before the nuclear tests and were therefore free of such radiation contamination, began.
A similar situation could easily occur in the world of AI, where data generated before the advent and spread of GAI will be the most valuable resource for building new models.
Although the proliferation of synthetic data that could halt the development of GAI is already present, the situation is sustainable for the time being. However, soon, to keep up the current pace of technological development, it seems essential to clearly label synthetic data. In addition to the technological aspects of the issue, this is also an important aspect of preventing disinformation, electoral manipulation, or even abuse of data protection. Although there are signs of similar legislative trends (e.g., in case of the EU), the global spread of similar legislation and the precise way in which it will be enforced is still an open question.
István ÜVEGES is a researcher in Computer Linguistics at MONTANA Knowledge Management Ltd. and a researcher at the Centre for Social Sciences, Political and Legal Text Mining and Artificial Intelligence Laboratory (poltextLAB). His main interests include practical applications of Automation, Artificial Intelligence (Machine Learning), Legal Language (legalese) studies and the Plain Language Movement.



