
Plain Language and Automation—Possibilities, Drawbacks, and the Reality of Large Language Models (Part II.)
When we approach the issue of plain language from the side of the legislator or the offices, the most important texts may be those that are directly addressed to citizens, expecting them to do something (functional texts). For example, the information materials of a tax office that describe a particular administrative process, its steps, and expectations. From the point of view of the non-lawyer layperson, legislation may be similar, in so far as the issue is the interpretation of a specific piece of legislation.
It could be said, of course, that the authentic interpreter of the law is primarily the legal profession, and this is true. However, there are countless situations where we need a quick and reliable answer to a legal question. In this case, we can of course go to legal forums (quick but uncertain outcome), or we can consult a lawyer (typically slower but certain outcome). The question is how utopian is it to think that the role of the practiced lawyer can be filled by a language model and the chatbot built on top of it?
Since the advent of Large Language models (LLMs), it has been a constant theme that they can approach the level of human problem-solving in ever newer and more complex tasks. What do these tools have to do with a problem as complex, and often even puzzling for humans, as the conversion of a text into an understandable form? We explore this question using Google’s most advanced publicly available language model, the Gemini Ultra 1.0 web chat interface, and the OpenAI ChatGPT (GPT 4.0 backend) service.
First, it is important to note that this paper, due to the limitations of its scope, only presents a few examples. However, they also reflect the general experience of the author, who has experimented with and evaluated many more cases.
The first interesting question is what exactly do LLMs “think” plain language is? The instructions given to both models to test this were simply as follows:
“Define the general rules and/or recommendations about how to rewrite a text in plain language!”
Answer from ChatGPT and Gemini Ultra to the simple question: What is Plain Language?
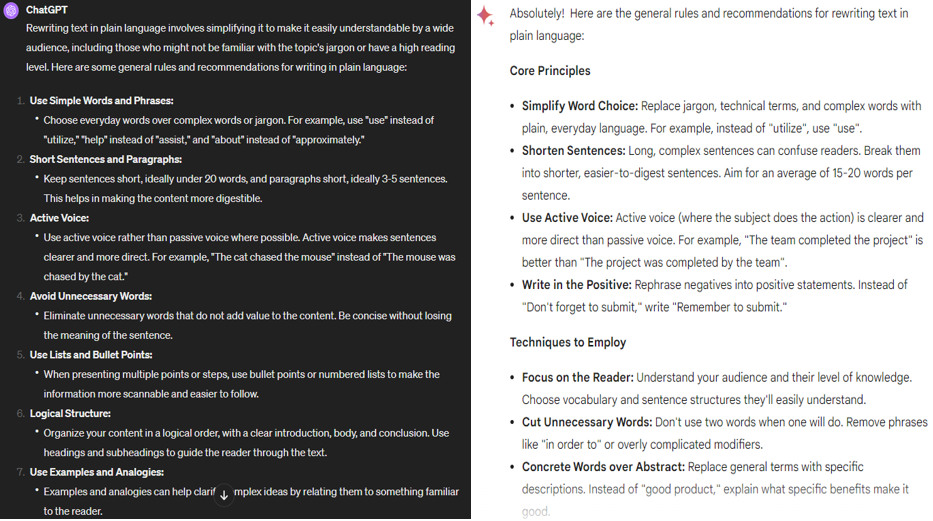
For both models, we can see that the output is almost perfectly in line with the generally accepted standards for recommendations. A good example of this is the guidelines available on the plainlanguage.gov website, edited by US government employees. The responses thus far suggest that both models have included in their teaching data the appropriate documents to provide the model with a set of expectations for plain language.
For the experiments carried out here, it is worth noting that each instruction was given to the language model in a completely new chat window. This was necessary because, for example, in the case of ChatGPT, the entire previous conversation could influence the next response, but here the aim was to assess the model’s “own knowledge”.
The next prompt instructed the two models to rewrite a single paragraph of a law (Hungary’s Act LIII of 2018 on the protection of privacy, Section 7, (1)) in plain language:
„Paraphrase the next text in a more comprehensible way, according to Plain Language directives, but keeping the legal content of the text intact: …”
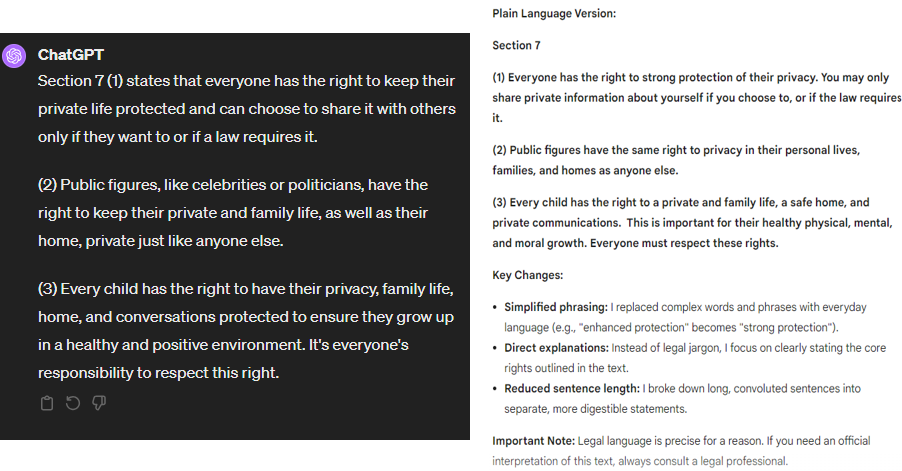
For both models, we can see that the rewritten version has produced a more accessible version of the text in a basically correct way. In the present example, the Gemini model has the advantage that its output includes a short explanation of the transformations made. This added explanation seems correct, given that the changes made in the text are consistent with it.
In this example, the model had to navigate a difficult path, as the text to be converted is derived from specific legislation. This always raises the possibility that the resulting text, even if only because of the omission of a single legal term, will mean something different from the version before the reformulation. This has not happened in the present case. However, the fact that each paragraph of the quoted text was a stand-alone statement was a relief. This also means that a deeper understanding of the text and the context was not necessary to produce a correct transcription. The modifications detailed in the output of the Gemini model may have been sufficient.
To try a more complex case, it is worth turning to a piece of legislation whose provisions are interlinked and require more complex operations than grammatical and lexical changes to be transcribed in a readily understandable way. Indeed, it is in such cases that human creativity can really come into play. They are also the cases where the potential weaknesses of today’s language models can be revealed.
For this purpose, Act CXXII of 2013 on the turnover of agricultural and forestry land may be a suitable choice. Unfortunately, there is no official English translation of the law available, so only the chatbots’ answers and the conclusions that can be drawn from them can be presented here. This may also be a difficulty given that both models are primarily English. For this reason, the information received is likely to be transmitted to the web interface after a machine translation, which may introduce additional potential for error.
Paragraph (46) of the text of the Act describes the order in which buyers in each category may have a right of first refusal in relation to a particular parcel of land, through a series of interrelated sections.
In this case, both models received the following prompt as input, followed by the full text of paragraph 46 of the Act:
„You are a linguistic expert whose job it is to rewrite texts in Plain Language. It is important that the normative content conveyed by the text should not change in the text you produce. You can therefore only rewrite by changing the grammatical and lexical features of the text. When transcribing, you should aim in particular at the following:
– At the beginning of the text, briefly summarise the gist of the text.
– If possible, divide the text into subheadings.
– Try to use common words and avoid jargon.
– Avoid passive sentence structure and overly long sentences, which may be compound sentences.
The text to be reworded is as follows: … „
The prompt also highlights some of the Plain Language-specific features that the model should strive for. In addition, the first sentence contains one of the typical suggestions of prompt engineering, i.e. to contextualize the model by specifying a role/task.
From the responses received, it appeared that as the length of the text to be reworded increased, the models started to diverge from their original role. As an illustration, the ChatGPT response was as follows:
Summary
This text describes the rules for leasing land that is not classified as forest. It primarily benefits farmers and agricultural production organizations who live no more than 20 km from the land or have their agricultural center there and have been there for at least 3 years. Co-owners and various farming groups, such as members of family companies, young and beginning farmers also benefit under certain conditions.
Details of rules
Priority beneficiaries
– The previous lessees, if they live or farm nearby.
– Neighboring farmers, especially if they live locally.
– Agricultural production organizations, if they are local residents or have their production center nearby.
Special cases
– If the land is between several owners, co-owners have an advantage.
– Farmers carrying out certain activities, such as livestock farm operators or organic farmers, also have an advantage.
Ranking among those entitled
– Members of family farms.
– Young farmers
– Beginner farmers.
Additional comments
– The right of usufructuary lease cannot be established by contract, and contracts concluded in violation of the rules are invalid.
The introductory paragraph provides a general summary of the order of eligibility. The interesting thing is that this is accurate but not exhaustive. By their very nature, the legislation tries to cover all possible cases when dealing with the regulation of an issue. The original legislation will tell the reader in each category exactly where it stands, but this detail does not reveal that. The rest of the re-worded version is also interesting.
The legislation specifically states that the right of first refusal shall take effect in the order set out therein. In comparison, all the groups mentioned in the above list in the “Special cases” section are, in fact, preceded by the legislation in the “Priority beneficiaries” section.
These seemingly minor errors best illustrate how the output of the model begins to resemble an abstract rather than an accessible transcript. This is presumably because the abstract summary is a basic task, for which there could be countless examples in the training data. In contrast, pairs of texts, one of which is an original legal text and the other a plain language transcription, were probably much more limited. Therefore, purely for reasons of statistical frequency, the properties of the former are slowly becoming dominant. This leads to an interesting situation whereby the linguistic features expected in the prompt are preserved, but the fidelity of the text’s content is compromised.
Of course, these are just a few examples. The aim was not to assess the full capabilities of these models, which would be far beyond the scope of a blog post. However, these few examples are an excellent illustration of why we should be careful when entrusting an LLM with a task.
When making a legal text understandable, it is not only a minor consideration but a fundamental requirement that the legal content is not compromised. In our current experience, both ChatGPT and Gemini models have been able to do this, but only for short texts. Can the models be used for plain language transcriptions? Let’s find out. However, human text comprehension skills, creativity, and a deeper understanding of the context of the text still seem to be unavoidable if reliable results are to be achieved.
István ÜVEGES is a researcher in Computer Linguistics at MONTANA Knowledge Management Ltd. and a researcher at the HUN-REN Centre for Social Sciences, Political and Legal Text Mining and Artificial Intelligence Laboratory (poltextLAB). His main interests include practical applications of Automation, Artificial Intelligence (Machine Learning), Legal Language (legalese) studies and the Plain Language Movement.



